AGENTS.md
AGENTS.md는 과연 효과적인 것일까
2026년 2월 공개된 AGENTS.md 평가 논문(Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? (arXiv:2602.11988v1))은, LLM이 생성한 컨텍스트 파일이 평균 성공률을 오히려 낮추고 비용을 20% 이상 올릴 수 있다고 보고했습니다. 비슷한 시기 OpenAI는 "큰 AGENTS.md" 접근이 실패했다고 밝히며, AGENTS.md를 짧은 목차로 축소하고 상세 지식은 docs/로 분리하는 운영 방식을 공개했습니다. 겉으로는 대척점처럼 보이지만, 두 메시지는 결국 같습니다. AGENTS.md의 효용은 "많이 쓰는 것"이 아니라 "작게 쓰고, 구조화하고, 검증하는 것"에서 나옵니다.
배경과 맥락
AGENTS.md는 원래 "에이전트를 위한 README"라는 아이디어로 확산됐습니다. 빌드/테스트 명령, 코드 스타일, 주의할 제약을 한 파일에 모아, 모델이 저장소를 더 빨리 이해하도록 돕는 목적이었죠.
문제는 채택 속도가 너무 빨랐다는 점입니다. "효과가 있다"는 직감은 널리 공유됐지만, 실제로 작업 성공률을 높이는지, 아니면 토큰만 더 쓰게 만드는지는 2026년 2월까지 거의 정량 검증이 없었습니다.
이번 arXiv 논문(2602.11988v1)은 바로 이 빈칸을 메웁니다. 동시에 OpenAI의 Harness Engineering 글은 대규모 에이전트 운영 경험에서 "무엇이 실제로 작동했는지"를 공개했습니다. 이 둘을 함께 봐야 AGENTS.md의 효용을 과장 없이 읽을 수 있습니다.
AGENTS.md, 실제로 도움이 되나: 2026년 논문 핵심 수치
논문은 SWE-bench Lite(대중 저장소)와 새로 만든 AGENTbench(138개 이슈, 12개 저장소)를 함께 사용해 세 조건을 비교했습니다.
- 컨텍스트 파일 없음
- LLM이 생성한 컨텍스트 파일
- 개발자가 작성한 컨텍스트 파일
핵심 결과는 다음과 같습니다.
- 개발자 작성 파일: 평균 +4% (무컨텍스트 대비)
- LLM 생성 파일: 평균 -3%
- 비용: 컨텍스트 파일이 있을 때 20%+ 증가
즉, "AGENTS.md가 있으니 무조건 좋아진다"는 결론은 성립하지 않았습니다. 특히 자동 생성된 장문 지침은 모델의 탐색·테스트·파일 순회를 늘리지만, 그 증가한 행동이 정확도 개선으로 항상 이어지지 않았습니다.
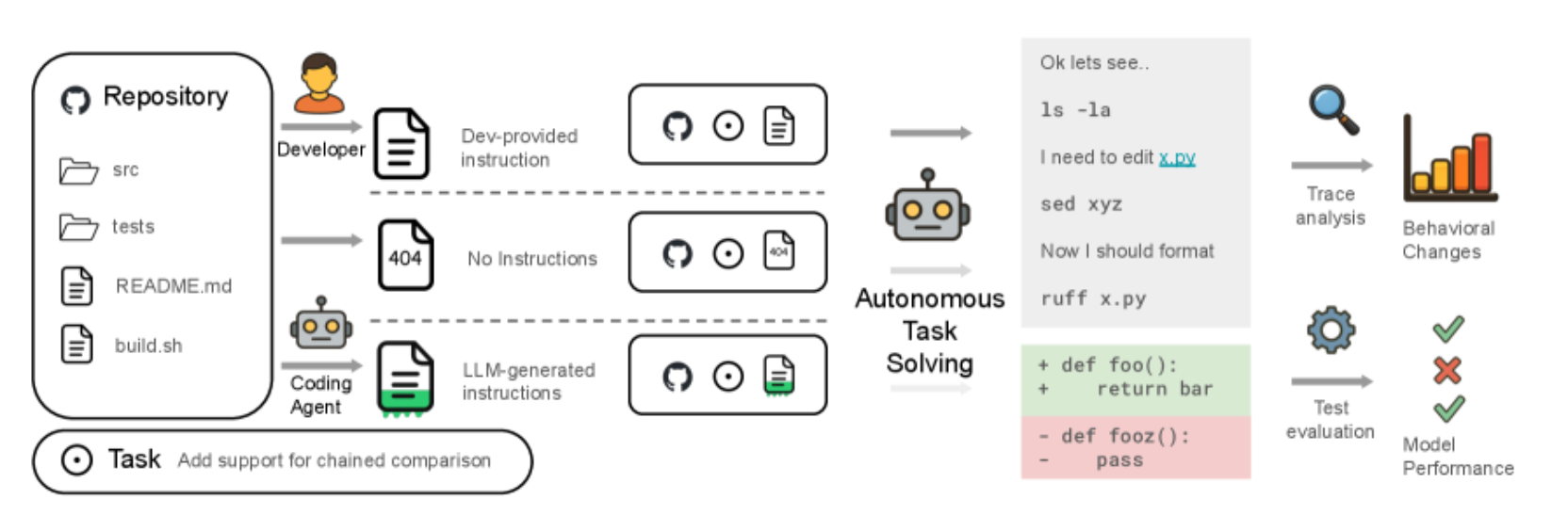
캡션: AGENTbench 논문 실험 파이프라인(무컨텍스트/LLM생성/개발자작성 비교).
OpenAI Harness Engineering과의 대척점: "큰 AGENTS.md"의 실패
OpenAI 사례는 표면적으로 논문과 대척점처럼 보입니다. 내부 베타 제품을 "직접 손코딩 없이" 운영하며 빠른 처리량을 냈다는 이야기 자체가 매우 공격적인 성공 서사이기 때문입니다.
하지만 AGENTS.md에 대한 결론만 떼어 보면 오히려 논문과 가까워집니다.
- OpenAI도 "one big AGENTS.md" 접근이 실패했다고 명시
- AGENTS.md를 백과사전이 아니라 "table of contents"로 축소
- 짧은 AGENTS.md(약 100줄) + 구조화된
docs/+ 린터/CI 문서 검증 + 지속적 doc-gardening으로 운영
핵심은 "문서를 많이 넣는 것"이 아니라 "에이전트가 필요한 시점에 필요한 깊이만 점진적으로 접근(progressive disclosure)"하게 만드는 정보 아키텍처였습니다.
충돌이 아니라 조건의 문제: 언제 AGENTS.md가 효용을 내는가
논문과 OpenAI 사례를 함께 보면, 충돌이 아니라 조건 차이로 읽는 게 정확합니다.
- 논문이 경고한 것: 과잉 요구사항이 들어간 컨텍스트 파일은 작업을 어렵게 만들 수 있다.
- OpenAI가 보여준 것: AGENTS.md를 작게 유지하고, 상세 정보는 구조화·검증 가능한 별도 문서로 관리하면 운영 효율을 만들 수 있다.
여기에 독립 실무 글(Logic Inc, 2025-12-30)까지 합치면 결론은 더 선명해집니다. 에이전트는 "좋은 코드베이스 습관"을 선택이 아닌 전제조건으로 바꿉니다. 테스트, 작은 파일, 빠른 검증 루프, 엄격한 경계가 없으면 AGENTS.md 문구를 늘려도 효과가 제한적입니다.
실무 적용: "AGENTS.md를 짧은 지도"로 만드는 5단계
- AGENTS.md를 100~200줄 내 "엔트리 포인트"로 제한합니다.
- 아키텍처/도메인/플랜/운영 규칙은
docs/하위로 분리하고 AGENTS.md에서 링크합니다. - AGENTS.md에는 변하지 않는 원칙(테스트 명령, 금지사항, 의존성 방향)만 둡니다.
- 자주 바뀌는 내용은 실행 가능한 검증(린터, 구조 테스트, CI)으로 승격합니다.
- 문서 신선도 점검(주기적 정리 PR)을 자동화합니다.
이렇게 하면 AGENTS.md는 "모든 걸 담는 문서"가 아니라 "에이전트가 길을 잃지 않게 하는 지도"가 됩니다.
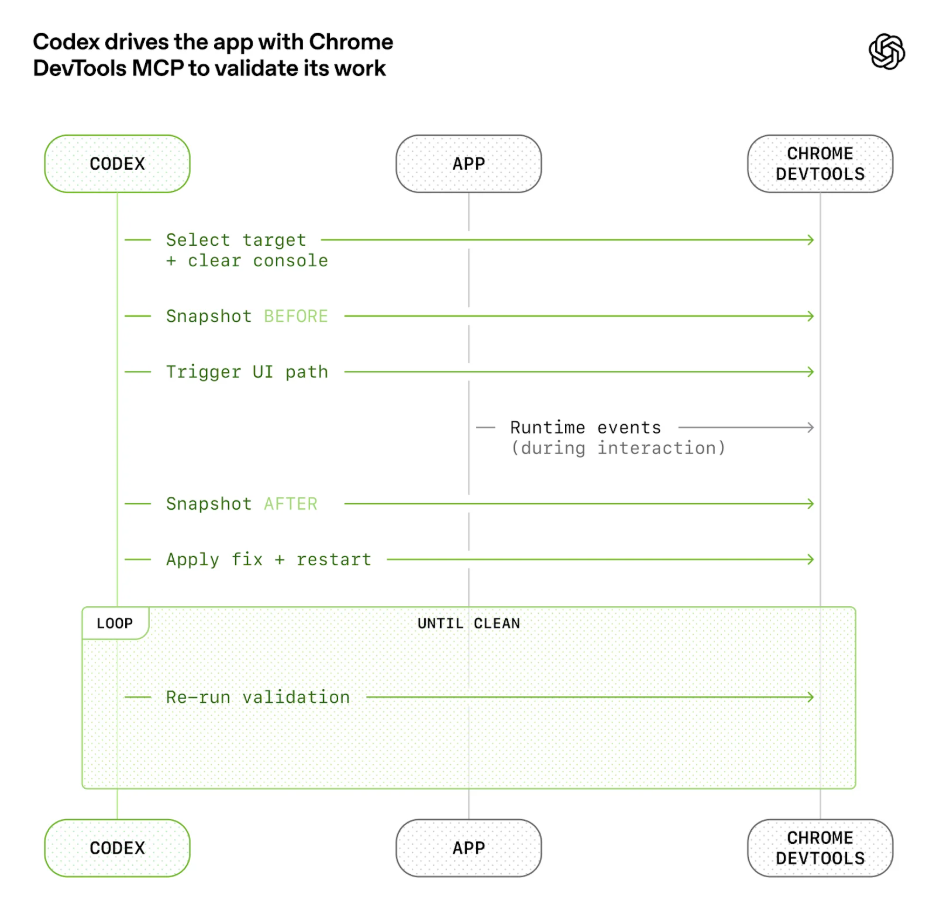
캡션: 에이전트 성능은 문서뿐 아니라 실행/검증 하네스 설계와 결합될 때 커진다는 점을 보여주는 사례 이미지.
한계점
- arXiv 2602.11988은 preprint(v1)라서 후속 검토 과정에서 일부 해석이 조정될 수 있습니다.
- OpenAI 글은 통제 실험 보고서가 아니라 특정 팀의 운영 사례이므로, 동일 투자(하네스·도구·검증 체계) 없이 그대로 재현되긴 어렵습니다.
- 따라서 지금 시점의 안전한 해석은 "AGENTS.md 자체의 만능성"이 아니라 "정보 구조와 검증 파이프라인의 품질"에 효용이 달려 있다는 수준입니다.
왜 중요한가
2025년엔 "AGENTS.md를 넣을까 말까"가 질문이었다면, 2026년 2월 현재 질문은 바뀌었습니다.
"AGENTS.md를 얼마나 길게 쓸까"가 아니라, "AGENTS.md를 얼마나 작은 지도로 유지하면서, 상세 지식을 얼마나 신선하고 검증 가능하게 분산할까"가 핵심입니다.
이 관점을 잡으면 문서가 에이전트의 사고를 방해하는 비용 항목이 아니라, 처리량과 품질을 동시에 올리는 운영 자산이 됩니다.
Sources
- Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? (arXiv:2602.11988v1)
- Harness engineering: leveraging Codex in an agent-first world (OpenAI, 2026-02-11)
- AGENTS.md 공식 사이트
- AI Is Forcing Us To Write Good Code (Bits of Logic, 2025-12-30)
- ARCHITECTURE.md (matklad, 2021-02-06)