AI #반도체 #Taalas
Taalas는 모델을 칩으로 바꾸기 시작했다
2026년 2월 19일, Taalas는 Llama 3.1 8B를 하드와이어드한 HC1을 공개하며 "모델을 맞춤형 실리콘으로 전환"하는 접근을 전면에 내세웠습니다. 공식 주장은 사용자당 17K tok/s, 기존 대비 10배 속도, 20배 구축비 절감, 10배 전력 절감입니다. 흥미로운 지점은 단순 양자화 최적화를 넘어, 모델 자체를 칩 구조와 함께 고정해 지연시간 병목을 줄이려는 시도라는 점입니다. 동시에 1세대에서 3/6-bit 양자화로 품질 저하 가능성을 인정했다는 점은, "속도 대 품질" 트레이드오프가 여전히 남아 있음을 보여줍니다.

캡션: Taalas가 공개한 HC1 보드. 모델-고정형 실리콘 제품의 실체를 보여주는 이미지. (출처: Taalas Mission Log)
배경과 맥락
생성형 AI 추론 비용과 지연시간을 줄이기 위한 시도는 이미 오래전부터 이어져 왔습니다. 대표적으로는 더 낮은 비트 정밀도(INT8/INT4/FP4/FP8 등)를 쓰는 양자화가 있고, 1-bit 계열 연구(BitNet, BitNet b1.58)도 이 흐름 위에 있습니다. 공통 목표는 동일합니다. 메모리 사용량, 전력, 지연시간을 줄여서 추론 경제성을 개선하는 것입니다.
문제는 저정밀화가 항상 "공짜 속도"가 아니라는 점입니다. NVIDIA TensorRT 문서도 양자화에서 반올림/클램핑 오차와 정확도 저하 리스크를 명확히 설명합니다. 즉 기존 접근은 대체로 "모델은 유지하고 표현 정밀도를 줄여 가속"하는 방식이었습니다.
Taalas는 여기서 한 걸음 더 나가 "모델을 칩으로 고정"하는 선택을 했습니다. 발표일은 2026년 2월 19일이며, 첫 제품은 하드와이어드 Llama 3.1 8B(HC1)입니다.
얼마나 개선됐나
Taalas 공식 발표의 핵심 수치는 다음과 같습니다.
- 사용자당 17K tokens/sec
- 기존 대비 약 10배 빠른 속도
- 약 20배 낮은 구축 비용
- 약 10배 낮은 전력 소비
성능 비교 그래프는 Taalas가 직접 제시했고, 일부 비교 기준으로 NVIDIA 및 Artificial Analysis 데이터를 함께 참조합니다. 절대 수치는 회사 주장이 포함되어 있으므로 독립 재현 검증은 더 필요하지만, "어떤 지표를 기준으로 경쟁하는지" 자체는 분명해졌습니다.
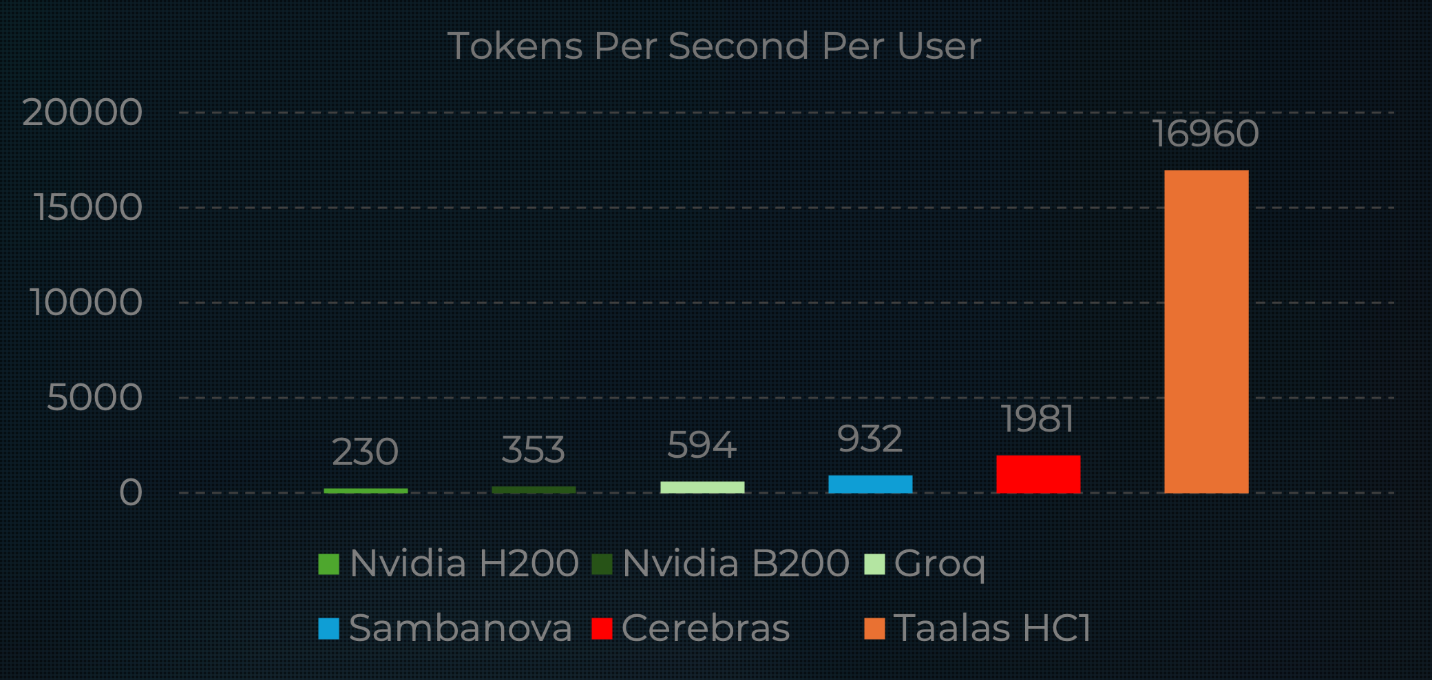
캡션: Llama 3.1 8B 기준 tokens/sec/user 비교 그래프. (출처: Taalas, 일부 비교 기준으로 NVIDIA/Artificial Analysis 인용)
기존 속도 개선 시도와 무엇이 다른가
기존 가속 시도(예: PTQ/QAT, INT8/INT4, 1-bit 계열 연구)는 보통 범용 하드웨어 위에서 모델 실행 효율을 높이는 전략입니다. 범용성과 업데이트 유연성이 강점입니다.
Taalas 접근은 반대로, 특정 모델을 하드웨어에 강하게 결합해 지연시간과 비용을 극단적으로 낮추는 전략입니다. 쉽게 말해 "소프트웨어 최적화"보다 "하드웨어 특화" 쪽으로 무게추를 옮긴 것입니다.
의미 있는 지점은 여기입니다. 이제 경쟁 축이 "누가 더 큰 GPU 클러스터를 쓰는가"만이 아니라, "누가 모델-하드웨어 동시설계를 더 빨리 반복하는가"로 이동하기 시작했습니다.
한계점: 칩 주기가 모델 주기를 따라갈 수 있나
Taalas도 한계를 숨기지 않았습니다. 1세대 HC1은 3/6-bit 양자화를 사용했고, GPU 기준 대비 품질 저하 가능성을 공식적으로 인정했습니다. 2세대에서 4-bit FP 포맷으로 보완하겠다고 밝혔지만, 이 자체가 "속도 최적화의 부채"를 시사합니다.
더 큰 구조적 한계는 일정입니다. 칩 업계 일반론(Reuters 보도 인용)에 따르면 첫 테이프아웃은 비용이 크고 완료까지 통상 약 6개월이 걸리며, 실패 시 재테이프아웃이 필요할 수 있습니다. 반면 모델 생태계는 분기 단위로 급변합니다. 이 간극이 커지면 "아주 빠른 칩 + 상대적으로 오래된 모델" 조합이 반복될 수 있습니다.
여기에 산업 뉴스도 같은 방향을 가리킵니다. OpenAI, Meta 등도 커스텀 칩을 확대하고 있지만, 실제 배치 속도는 단계적이고 물리적 제약(패키징, 다이 크기, 제조 리드타임)을 피하지 못합니다. 즉 Taalas의 방향은 선명하지만, 성공 조건은 기술 데모가 아니라 반복 가능한 공급망/개발 주기 최적화입니다.
어떻게 써볼 수 있나
지금 당장 체험할 수 있는 경로는 두 가지입니다.
https://chatjimmy.ai/: 공개 챗봇 데모https://taalas.com/api-request-form/: API 접근 신청
실제로 ChatJimmy는 로그인 없이 바로 질의가 가능했고, 응답 하단에 생성 시간과 tok/s가 표시됩니다. 데모 기준으로는 "지연이 거의 느껴지지 않는 대화"라는 인상을 빠르게 확인할 수 있습니다.
캡션: ChatJimmy 공개 데모에서 응답 속도 지표(Generated in, tok/s)가 표시되는 화면. (출처: chatjimmy.ai)
왜 중요한가
이번 발표의 의미는 "속도가 빠르다" 자체보다, 가속 전략의 단위가 바뀌고 있다는 점에 있습니다. 과거에는 모델을 기존 하드웨어에 맞추는 최적화가 중심이었다면, 이제는 모델-하드웨어를 함께 설계해 추론 경제성을 재정의하려는 시도가 본격화되고 있습니다.
다만 이 전략이 산업 표준이 되려면 두 가지를 동시에 만족해야 합니다. 첫째, 품질 손실 없는 저정밀/특화 설계. 둘째, 모델 업데이트 속도와 칩 양산 속도의 간극 축소. Taalas는 첫 신호를 보여줬고, 이제 남은 질문은 "지속 가능한 반복 속도"입니다.
Sources
- https://taalas.com/
- https://taalas.com/products/
- https://taalas.com/mission-log/
- https://taalas.com/the-path-to-ubiquitous-ai/
- https://chatjimmy.ai/
- https://arxiv.org/abs/2310.11453
- https://arxiv.org/abs/2402.17764
- https://docs.nvidia.com/deeplearning/tensorrt/10.12.0/inference-library/accuracy-considerations.html
- https://docs.nvidia.com/deeplearning/tensorrt/latest/inference-library/work-quantized-types.html
- https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference
- https://simonwillison.net/2026/Feb/20/taalas/
- https://www.investing.com/news/stock-market-news/exclusiveopenai-set-to-finalize-first-custom-chip-design-this-year-3858500
- https://engineering.fb.com/2025/09/29/data-infrastructure/metas-infrastructure-evolution-and-the-advent-of-ai/