gpt-oss: OpenAI의 첫번째 오픈소스 모델 공개
2025년 8월 5일, OpenAI는 gpt‑oss라는 새로운 오픈‑소스 모델 시리즈를 공개했습니다.
gpt‑oss‑120b 와 gpt‑oss‑20b 두 모델은 모델 가중치를 완전히 공개한 최초의 GPT‑계열 모델로, 자유로운 커스터마이징과 연구에 초점을 맞춥니다. 모델은 MoE(Mixture of Expert) 구조를 사용해 전체 파라미터 대비 활성 파라미터 수를 줄이고, “하모니” 응답 형식을 통해 체계화된 대화 포맷을 제공합니다. Apache 2.0 라이선스로 공개되어 상업적 사용 및 수정이 가능한 이 모델의 주요 내용과 구체적 사용방법(Ollama, vLLM, Transformers)을 뉴스레터에서 같이 확인해보시죠!

모델 주요 특징
| 모델 이름 | 총 파라미터 | 활성 파라미터 | 전문가 수/활성 전문가 | Transformer 블록 | 최대 컨텍스트 |
|---|---|---|---|---|---|
| gpt‑oss‑20b | 20 B | 3.6 B | 32 / 4 | 24 블록 | 128k tokens |
| gpt‑oss‑120b | 117 B | 5.1 B | 128 / 4 | 36 블록 | 128k tokens |
OpenAI는 이번 발표에서 2개의 모델을 공개했습니다. 하나는 120B규모의 모델이고, 하나는 20B 사이즈의 모델입니다. 두 모델이 가지는 기술적 특징에 대해서 살펴봅시다.
MoE 방식을 적용한 모델
모델 사이즈가 커보일 수 있지만, MoE(Mixture of Expert)구조를 사용해서 실제로 활성화되는 파라미터의 수는 적어서 빠른 연산 속도를 보장할 수 있습니다. MoE는 특정 분야에 특화된 모델을 여러개 결합하여 각 모델 중 사용자의 질문에 맞는 모델만 사용하여 추론을 함으로서 성능은 올리고, 자원 사용과 속도는 향상시키는 기술입니다.
이를 위해서는 모델 앞에 라우터 레이어를 두게 됩니다. 이 라우터에서 여러 개의 모델 중 어떤 모델을 사용할지 결정하고, 해당 모델들만을 사용하여 추론을 하게 됩니다. gpt-oss에서는 여러 각 토큰당 소수의 전문가(4개)만 활성화돼 계산량을 줄입니다
표를 보시면, 활성 파라미터수와 활성 전문가 수라는 지표를 확인해보실 수 있습니다. 이는 전체 모델의 수와 파라미터(모델의 크기) 대비 일부를 사용해서 모델을 추론한다는 의미입니다.
모든 작업을 할 수 있는 큰 모델 하나만을 쓰면, 그만큼 연산량과 필요한 GPU의 크기가 커집니다. 큰 모델만큼 다양한 분야는 잘할 수 없지만 최소 한 분야에서는 전문가 만큼의 성능이 보장되는 작은 모델을 사용한다면, 사용자의 질문에 맞게 여러 전문가 모델만 사용하게 되고 이는 동일한 성능을 더 작은 자원만을 사용하여 추론할 수 있다는 이점이 생기게 됩니다.
Chain-of-Thought(CoT)
CoT는 모델이 답을 만들 때, 사슬(Chain)처럼 여러 생각을 이어나가서 답을 만들어내어 높은 성능을 보장하도록 하는 기법입니다. GPT를 사용할 때, 'N초 동안 생각함'과 같은 문구와 함께 여러 추론 과정을 보여주는 것을 보신적이 있으실 것 같은데요, 이 CoT 기법의 생각 과정을 보여주는 것입니다.
이번에 공개한 모델도 CoT를 기반으로 만들어졌습니다. 이는 모델의 추론 결과에 대해 신뢰성 확보에 유용합니다. 만약 A라는 답변을 낼 때, CoT가 실제 정답을 만들기 위한 과정과 일치하지 않는다면 정답이더라도 이런 생각의 흐름을 프롬프트를 통해서 수정할 수 있기 때문입니다. 이를 통해 프롬프트를 개선하고, 복잡한 추론 과정도 손쉽게 수행할 수 있게 됩니다.
모델 아키텍처
그 위에도 여러 모델 아키텍처를 사용해서 모델의 성능을 올렸습니다. SwigGLU 활성화 함수(Activation Fucntion)를 사용하고, RoPE 포지셔널 인코딩을 사용한다고 합니다. 출처
활성화 함수는 모델의 표현력을 늘리기 위해 '비선형성'을 추가하는 함수를 의미합니다. 포지셔널 인코딩은 GPT 구조에서 각 입력 토큰의 위치 정보를 알려주기 위한 방법입니다. 이를 통해 128k 토큰이라는 긴 입력도 한번에 처리할 수 있게 되었습니다.
또한, FP4 (또는 MXFP4) 양자화를 사용하였습니다. 컴퓨터에서는 소수점 아래를 표현하고자 한다면, 모든 소수점 아래를 메모리 어딘가에 두어야 합니다. 더 많은 소수점 아래 숫자를 연산하거나 저장하려면 더 많은 양의 연산과 메모리를 필요로 합니다. 보통은 fp16, fp32를 많이 사용합니다. 이 모델에서는 fp4를 사용하고 있습니다. 많은 연구에서 fp보다는 파라미터의 수(120B, 20B)가 성능에 더 큰 영향을 준다는 것으로 알려져왔기 때문에 fp연산의 정확도를 포기하고 파라미터 수를 늘렸습니다.
그렇기 때문에 gpt‑oss‑120b는 단일 H100 GPU에서도 실행 가능하며, gpt‑oss‑20b는 16 GB 이하의 메모리에서도 실행됩니다
모델 성능 및 속도
NVIDIA 기술 블로그에서는 gpt‑oss 시리즈의 하드웨어 요구와 성능을 공개했습니다. 기록에 따르면 gpt‑oss‑120b와 gpt‑oss‑20b는 Blackwell 아키텍처를 활용한 NVL72 시스템에서 초당 최대 150만 토큰(tps) 을 처리할 수 있습니다. 또한 대형 모델 (gpt‑oss‑120b)의 학습에는 H100 GPU 20만 대 시간 이상, 즉 210만 시간 이상이 소요되었으며, 작은 모델은 그보다 약 10배 적은 계산량으로 훈련됐다고 밝혔습니다.
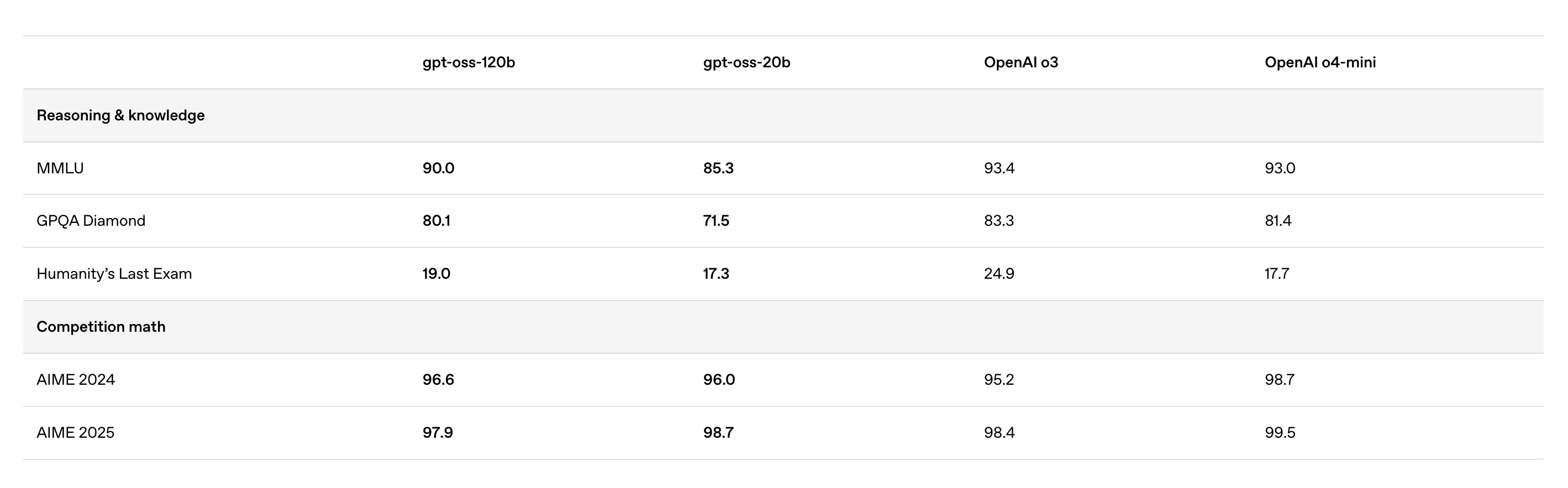
성능 또한 나쁘지 않습니다.
OpenAI의 closed 모델 중 최고 성능인 o3, o4-mini와 비교해도 크게 뒤쳐지지 않는 성능을 보입니다. 외부 API를 호출할 수 없는 폐쇄망 환경에서는 이 모델을 사용한다면, 큰 어려움 없이 바로 서비스 할 수 있는 수준의 모델입니다.
직접 사용해보기
오픈AI가 오랜 기간 이 모델을 공개하기 위해 기다렸다는 것을 알 수 있었습니다. 왜냐하면, 공개 직후부터 다양한 플랫폼을 지원하도록 준비했기 때문입니다. Transformers, Ollama, vLLM과 같은 대표적인 오픈소스 서빙 프레임워크 뿐만 아니라, AWS, Fireworks와 같은 여러 클라우드도 지원하고 있습니다.
웹에서 바로 사용해보기
gpt-oss.com에서 바로 사용해보실 수 있습니다. 모델은 궁금한데, 코딩이 익숙하지 않거나, 바로 사용해보고자 한다면 위 링크를 사용할 수 있습니다.
Transformers 라이브러리
- 필요한 패키지를 설치합니다.
pip install -U transformers kernels torch
- 모델 로드 및 추론
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics."},
]
outputs = pipe(messages, max_new_tokens=256)
print(outputs[0]["generated_text"][-1])
Ollama 사용하기
위 방법을 통해 손쉽게 모델을 사용해볼 수 있습니다. ollama라는 플랫폼을 사용해볼 수도 있습니다.
ollama pull gpt-oss:20b
ollama pull gpt-oss:120b
추론 강도(Reasoning Level) 설정
사용하시다보면 모델의 추론 강도를 설정하는 부분을 마주하셨을 것입니다.
이는 앞서 말한 CoT의 추론을 얼마나 많이 혹은 적게 하도록 할 것인지 설정할 수 있는 부분입니다. 모델은 시스템 프롬프트를 통해 Low, Medium, High의 세 가지 추론 강도 중 선택할 수 있습니다. 어떤 강도를 설정해야할지 모르겠다면 아래를 참고해보면 좋을 것 같습니다.
- Low: 빠른 응답과 일반적인 대화에 적합.
- Medium: 속도와 세부 정보의 균형을 유지.
- High: 깊이 있는 분석과 장문의 응답을 제공하지만 속도는 느립니다.
모델을 사용해보며
여러 오픈소스 모델이 최근에 많이 등장했습니다. 여러 성능 좋고 가벼운 모델이 많이 등장했지만, closed source 모델만큼 좋은 모델은 많이 없는 상황이었습니다. 더 많이 써봐야 알겠지만, 첫 인상으로는 그래도 꽤 쓸만한 오픈소스 모델이 나왔다고 느끼고 있습니다. OpenAI인데 공개된 모델을 오픈하지 않으니 "ClosedAI"다 라는 놀림을 받았던 OpenAI가 당분간은 놀림을 받지 않을 것 같습니다.
그래도 아쉬운 점은 있습니다. 최근에는 많은 모델이 음성이나 비전을 지원하는 '멀티모달'을 지원하고 있고, gpt의 여러 모델도 이미지나 오디오를 지원하고 있지만 이번 모델은 오디오나 이미지를 지원하지 않는다는 점입니다.
그래도 꽤나 높은 성능과 tool, agent에 특화된 성능으로 공개된 모델로 추후 어떤 소프트웨어와 기술이 이어서 등장하게 될지 기대해볼 부분도 많은 것 같습니다. 최근 한국 정부가 한국 특화 LLM을 만들겠다고 여러 투자를 이어가고 있는데요, 이번 OpenAI의 모델보다 좋은 모델이 개발될 수 있기를 기대해봅니다.